
In this post I’ll talk about NoSQL, what it is, why it is important, and what is wrong about it. In Part 2 I’ll present and alternative: a new concept that my co-author and I coined in a recent paper: NoDatalog, and explain how it can give us the benefits of NoSQL, but without the disadvantages (at least in theory…)
Once Upon a Time…
… only relational (SQL) databases walked the earth. They were based on a well-founded theory, well standardized and therefore you could start your application with one database, and as it gains on users move to a more robust, though more expensive one.
Relational database are based on tables that typically have fixed-width columns. The advantage is that the DB software could calculate the address of each row on disk by multiplying the row index by the row size, but the down side was that if I have an object, say a customer order that contains multiple items, I cannot express it as a single record. It needs to be split into multiple records, e.g., one for the order and one for each item, and link them through and order ID.
To be able to synchronize between them, relational databases use transactions. Transactions are a way to bundle database operations together in a way that for anyone querying the database at any given time, either the whole transaction is visible, or none of it. For example, if we created a new order with 5 items, either you can see the entire order, or none of it. You will never see an order with only three items…
If you started a small application using, e.g., Ruby on Rails, your application probably started by running on a single server, containing both the DB and the Web server. Then, as your application becomes more successful, more users are using the application and a single server is not enough. Adding Web servers is easy. You just add them. With today’s cloud IaaS prices constantly going down this is super easy, and not very expensive. Unfortunately, adding more servers for the DB does not have the same effect. The main reason is transactions. While databases are typically implemented to allow transactions to run in parallel, they are still committed in sequence. This means that regardless of how many computer nodes you can spare for a DB, there are just so many transactions per second your application will endure.
NoSQL
NoSQL came out of exactly this need. Relational databases are just not scalable enough. The term NoSQL is not a scientific one. It started as a hashtag for discussions about this new kind of databases. There are many kinds of databases referred to as NoSQL, but in this discussion I’ll only address a subset of them, which can be characterized as follows:
- Less-than-sequential consistency (typically strong or eventual consistency).
- High availability (no single point of failure, typically resistance to both node and network failures, up to some level).
- Flexible data model (JSON documents, rows with arbitrary columns, or arbitrary files).
- No support for fancy queries (typically, some extension of the key/value model).
High availability goes hand in hand with scalability, and goes against consistency. The more consistency we require, the more coordination we need between our nodes, the more we depend on them being up and connected, and the longer we need to wait for them to answer. If we don’t care that much about consistency, we can work even if some nodes are down or unreachable, and is we can work without some of the nodes, the user does not have to wait while we contact them.
NoSQL databases get away with less consistency by having a more flexible data model. When the data model is flexible (we are no longer restricted to fixed records), we can place our entire customer order in the same place (document, row or whatever). Then, when we make a query, we will either get it or not, but we will never get a partial order, because it is all stored together. If it was recently changed, we might get the previous version. But eventual consistency guarantees that eventually we will see the latest version.
In this post I will focus on the last bullet: “No support for fancy queries”. This is important to NoSQL because NoSQL is based on the notion of sharding, where different portions of the data reside on different machines. This is what makes them scale so well: each machine only cares about a fraction of the data, and as my data grows, I add more machines so that every machine needs to store a smaller fraction. If I can bundle things together (e.g., an order and its items), all I need to do in order to retrieve it is to go to the right machine (one of the few that hold this piece of data), and fetch it. I do not need “fancy queries”, like SQL joins, to retrieve my data. Or do I?
The Simplified Twitter Model
Eric Evans, one of the core developers of Cassandra (a popular NoSQL database), wrote a nice blog post about how to implement a twitter-like system using Cassandra. I like this example as it lays out the differences between the “old” way of doing this kind of things (using SQL), and the “new” – NoSQL way.
The Simplified Twitter Model is a name I gave a small subset of the Twitter data model. The model includes users who may follow other users, and tweets made by users. A user may query for his or her timeline, which is an aggregation of all tweets made by users this user follows. In SQL, this data model can be represented using the following three tables:
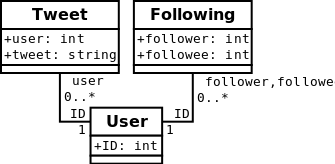
In order to retrieve one’s timeline, one needs to perform the following SQL query (? represents the user input):
SELECT user, tweet FROM Tweet, User, Following WHERE user = ID AND followee = ID AND follower = ?
This is all nice and simple, but as I wrote earlier, will not scale much. NoSQL to the rescue!
Doing this in NoSQL requires a bit of thought. Recall that NoSQL databases aggregate data and stores different aggregates on different machines. Since we want to get our timeline fast we cannot collect data from different machines. We want it all in one place. So the question is, how do we organize our data to this end?
Evans suggests that we de-normalize the data. What this means is that instead of storing each tweet once, we will store each tweet multiple times – once per each follower.
It goes like this: When a user tweets, Twissandra (the example system built by Evans) queries for that user’s followers. For each follower it places the tweet in that user’s timeline. The code below shows how:
# Get the user's followers, and insert the tweet into all of their streams
futures = []
follower_usernames = [username] + get_follower_usernames(username)
for follower_username in follower_usernames:
futures.append(session.execute_async(
timeline_query, (follower_username, now, tweet_id,)))
for future in futures: future.result()
So unlike the SQL example, here the timeline is an actual table (or a column family, or a document…) and not a query. The query to get the timeline is a piece of cake… really… but putting the data there (and making sure it is always correct and up to date) is a totally different story.
In Twissandra, only this denormalization loop exists, because users don’t see tweets made by other users before they started following them. To implement the equivalent of the above SQL query, you need four loops: One for when a tweet is added (the one we have), one for when a following is added, one for when a tweet is deleted and one for when a following is cancelled. And in all this, we need to make sure we don’t have bugs (e.g., that all loops are symmetrical), and that we do not suffer from consistency issues that cause certain tweets to never be displayed for a certain user.
This is just a simple data model. Imagine the full Twitter data model… how complicated it must be… and to think that every time a join needs to be made between two (or more) “tables” some loop has to run in order to put the data in the right places…
Now imagine you wish to upgrade your software. Imagine you would like to add a “time” dimension to your timeline, so that each timeline entry will have a timestamp. Even if you have the data for that already in the tweet, this means you need to write a run-once piece of software to add the (correct) timestamp to each timeline entry. This is a manifestation of the well-known data migration problem, that exists in any kind of database today. However, if your database is normalized, you only need to migrate the database where the format of the original data changes. For a denormalized database you’ll need to also migrate whenever queries change. And that happens a whole lot more often.
Next Time…
On Part 2 I’ll present an alternative I call NoDatalog. It takes a lot from NoSQL, but its roots come from another brand of databases known as deductive databases. I’ll explain why I think NoDatalog is a good alternative for most uses of NoSQL, and how it overcomes NoSQL’s limitations.

[…] Part 1 of this post I covered the NoSQL movement, and described what I think is not ideal there. A short […]
LikeLike
[…] simplified Twitter model is something I already introduced in my post on NoDatalog and NoSQL. It is a simple example application in which users can tweet, follow other users and display […]
LikeLike
[…] example I’ll give is the micro-blogging application example I’ve been using time and time again. The idea is simple: users tweet and follow other users. Eventually we need to present […]
LikeLike