
If you read my previous posts here or saw some of my Cedalion videos, you probably understand that the Cedalion programming language is different than most other languages. It is different in how it treats syntax, and in how it relates to editing. In this post I will elaborate about this different approach, named projectional editing, why it was chosen for Cedalion and what it means for you if you want to use Cedalion.
From Graph to Text
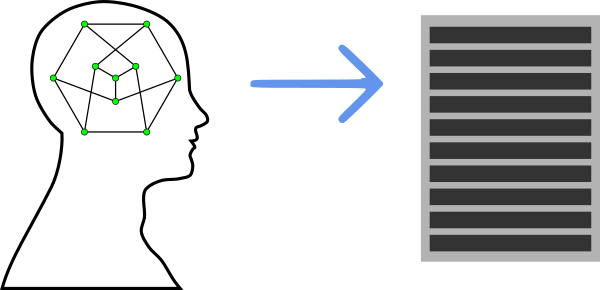
A program has two representations. One representation is what we see: a sequence of characters on the screen (I hope nobody nowadays prints code on paper… such a bad use for dead trees…) built into identifiers, keywords, literals and punctuation. The second representation is in the form of a graph, nodes connected by edges, representing the meaning of the problem. I like to think of writing new code as a process that starts with a graph that is embedded in our brain. Why a graph, you may ask? Because we think of things in terms of concepts and relations between these concepts. These map to nodes and edges. If this is the situation, we make a few graph transformations in our head, transforming the high-level conceptual model of what we want to write into a more elaborate though simpler graph representing the code we actually want to write. Finally we convert this graph to text, and type this text on the keyboard.
Imagine you need to implement a function that calculates income tax one needs to pay based on income and expense data given to you as input. At the beginning, you think in term of expenses, deductibles, income tax, etc. This is known as the problem domain. Each of these is an individual concept, and there are connections between them. For example, income raises the tax due, but deductibles reduce it. The mental graph you start with is therefore a description of the problem domain, focused on the particular problem you need to solve. Then, in your mind, you convert this graph into another graph, where the concepts are those of your programming language. For example, you may convert income and expense data into structures stored in arrays, deductibles into Booleans, and tax calculations into arithmetic operations.
(OK, I oversimplified this process… In real life you don’t “compile” an entire problem into code in your head. You do it step by step, with trial and error, but you do convert an idea of the problem into an idea of a program, both can be seen as graphs)
Finally, when your mental graph is ready, you can convert it to code. This is a simple conversion. If the graph was held by a computer and not your brain, translation to code could be implemented as a traverse of the graph (walking from node to node on the edges), while printing text related to each node we visit.
And why do we bother to write all this text? To that the implementation of our programming language could parse it back into a graph, of course…
From Text Back to a Graph
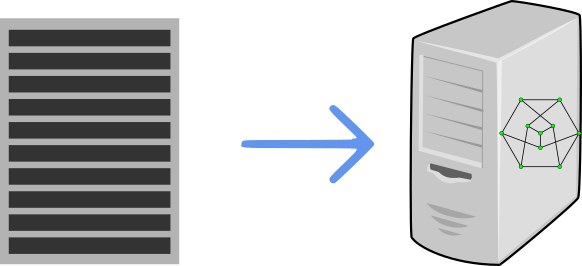
So now we take this program that we wrote as text, and we want a computer to run it. So we feed it to the implementation of our programming language, be it a compiler (for languages such as C, C++, C# or Java) or an interpreter (for languages such as Python, Ruby or JavaScript), and have them either run our program or translate (compile) it to some binary executable format.
So what is the first thing these language implementations do with our code? They translate it back into a graph. This graph is not the exact graph we had it our mind, after all, every person thinks of things (even of programming languages) a little differently, but it is very similar. This graph is often called an Abstract Syntax Tree or AST for short. It is called a tree because it is generally built as a tree, where the complete program (or actually, compilation unit — a single compiled file) is represented by the root node, and it is further divided, e.g., into classes, functions, statements, expressions, literals etc. This tree is the result of the parsing operation, which is the process of taking text and “understanding” it in form of a tree. Our AST is then refined by a step called semantic analysis, a step in which identifiers (which are often represented as leaf nodes in the tree) become edges in the tree. For example, in the following C function:
float square(float x) {
return x*x;
}
the original AST gives a separate leaf node for each of the three occurrences of x, but semantic analysis will realize that all three occurrences in fact refer to the same variable, and draw edges from its definition (in the first line) to both its uses in the second line. This makes our AST actually a general directed graph (semantic analysis will also check that all occurrences of x are of the same type or of compatible types, but we are not discussing types here).
This process of creating a graph out of text, and mainly its first part — parsing, complicates the design of programming languages significantly. I’m not talking about the challenge in parsing per se. While this is a challenge, with active research happening all the time. However, for the everyday programming language developer (if such a thing exists) tools like Yacc and its predecessors, or ANTLR already exist, and for the vast majority of languages they are enough.
Why This is Hard
So, why does parsing complicate the design of programming languages? Mainly because it makes decisions made in the early stages of defining a language very critical as the language evolves.
Keywords are one easy-to-notice part of the problem. Keywords are part of the syntax of a language. In most programming languages, keywords (also called “reserved words”) are words that are reserved by the language to play a part of its syntax, and these words are therefore not available for identifiers. In C, for example, “for” is a keyword, so you cannot call a variable or a function “for”. Small price to pay to have a clear syntax.
So how is this a problem? Because it makes it hard for languages to evolve. Consider C++ as an evolution of C. One of the design goals of C++ was that C programs would still be legal in C++. This is nearly true, but not exactly. Beyond some really dirty tricks that were legal in C and were deliberately outlawed in C++, C++ also introduced some new keywords such as “class” and “template”. In C, the following is a legal statement:
int class = template + 5;
However, in C++ this is invalid syntax. This is one of the reasons why C++ was not introduced as a new version of C, and the C programming language continued to evolve by itself. However, this illuminates the problem with keywords: new versions of a programming language cannot add new keywords without breaking existing code!
(JavaScript is one language that took this problem under advisement early in its evolution and added keywords such as “class” to the language long before they were actually given meaning. In addition, JavaScript allows keywords to be used as field names of an object, so “my.new.class” is a valid expression, as long as “my” is not a keyword. This mitigates the problem to some extent, but still does not solve it)
Keywords are just one example for this problem of language evolution. Basically, every new syntax added to a language must be evaluated to see that it does not collide with some syntax that already exist. Although this looks trivial, the huge number of combinations of possible combinations of language constructs makes the task of extending the syntax of a language so very challenging.
Where do we Need it the Most?
Because of the challenges I described above, most programming languages evolve slowly. Every such change will affect all users of that language, and therefore language designers want to be careful and get it right. But this has an unfortunate consequence. Remember the mental graph we start the programming process with? The nodes from that graph comes from the problem domain, and therefore, this graph is (relatively) small. In the process of turning it into a program we then break it down into a graph containing more, simpler nodes that come from the programming language. What if we didn’t have to do this part? What if we could program using problem domain elements?
For that to happen, we need a language that speaks our problem domain (e.g., the wonderful world of income tax laws, in our example above). Such a language is called a Domain-Specific Language (DSL). It is not realistic to expect that someone will do this for us, so it’s up to us to do this. Unfortunately, this puts us in a situation where we are the ones how need to take care of the evolution of the DSL, and we need to do it along with the evolution of our software. As I wrote earlier, language evolution is hard even for experienced language designers, so how can we expect that to be easy enough for us?
Projectional Editing
The term projectional editing was coined by Martin Fowler as a way to describe language workbenches such as MPS. What does this term mean? My definition of this term is simply the MVC architecture applied to code. What is considered “code” under this definition? I don’t think there is a strict line here. Does a visual HTML editor (such as the one I’m using right now to write this post) qualify? Maybe. Does a graphical editor for some modeling language qualify? Probably. But the case that I believe was in Fowler’s mind when coining this term is MVC-architecture applied to textual-looking code.
What does “textual looking” mean? Think of all the textual programming languages you know… That’s it. They are textual looking. Of-course, once you change the editing approach to projectional, these languages will not be textual anymore (or at least, not with the same syntax you’re used to).
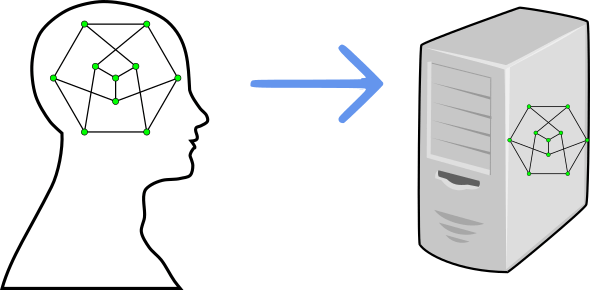
With projectional editing, the thing that is saved to disk — the thing you edit — is the AST of your program. MPS uses XML to save programs to disk. Even if you use their Java-like base language, you’ll see Java on the screen, but you’ll actually be editing an XML.
Projectional editing is therefore the closest you would probably get to transferring your mental graph directly into a graph on the computer.
The “Editing” Part of Projectional Editing
How do you edit in a projectional editor? Unlike a text editor, where the answer is simply “you type in text“, for projectional editing there is no single answer. Actually, every editor or language workbench is free to invent its own editing methods. Although there is no “gold standard”, some editing methods are common to most projectional editors.
- Top-down editing: You select a placeholder (some empty space), type the beginning of the name of the concept you wish to place there, and select the concept you want from an auto-completion menu.
- Bottom-up editing: Like top-down editing, just that you start with a space that is already occupied and select something to augment it. For example, you start with the number 1, and you select a plus (+) operator to get “1+_” (where _ is a placeholder for the right-hand operand).
- Special Actions: Some kinds of language concepts (or AST node-types) are associated with special commands or actions for editing. For example, a list can be associated with insertion and deletion operations. These actions can usually be selected from a menu, or can have keyboard shortcuts associated with them.
- Copy and Paste: Copy and paste operations can take entire sub-trees of the AST and copy them to another place in the AST. This is unlike textual copy and paste, which can copy arbitrary text and place it anywhere.
Why is Projectional Editing so Great?
Projectional editing requires some getting used to. You can’t just type your code like you’re used to. You need to understand and respect the tree structure.
When you do get used it, it opens a world of opportunities to you. In projectional editing the textual form of your code is only meant for you. Not for the computer. This means that it can be tweaked to best suite a human reader, and does not have to satisfy the need for unambiguous syntax. This means, for example, that you don’t need things like curly braces, semicolons or even quotes to tell the programming language where one thing ends and another thing starts. You can use colors as part of your syntax (unlike syntax highlighting, in which colors are added by the editor based on understanding the syntax). Additionally, you can use special symbols, different layouts and more.
But none of these reasons are why projectional editing was invented. It was invented because it allows languages to evolve. When you make your own DSL you want to make sure you will always be able to grow it, and to combine it with other DSLs, ones that were not purposely built to work with yours. With parsing, such evolution and combination is difficult as hell. With projectional editing, it is easy and natural. A new DSL is simply a new set of node-types you can add to your tree. More possibilities, not less. Because you select your nodes explicitly (using auto-completion menus or by other means) you will not get into ambiguities. You tell the editor exactly what you mean.
Projectional editing is new technology, and more than that — it is disruptive technology. Many of the tools in our existing ecosystem do not work well with projectional editing. But the ecosystem will not be there by itself. A community needs to build it, and for that to happen a community needs to exist. I hope this post shed some light on what projectional editing is and why it matters. If you want to try it yourself, please feel free to try either Cedalion’s tutorials or the MPS tutorials.

[…] thing that makes Cedalion special is the fact that it uses projectional editing. For those not familiar with this concept, the idea is that unlike most programming languages, […]
LikeLike
Great post! Let me leave my hobby projectional editor here: https://www.youtube.com/watch?v=s05SlmZ7ZPc
LikeLike